Metamorph: Injecting Inaudible Commands into
Over-the-air Voice Controlled Systems
Overview
Audio adversarial examples. Driven by deep neural networks (DNN), speech recognition (SR) techniques are advancing rapidly and are widely used in practice. However, recent studies have investigated a crucial problem --- Given any audio clip I with transcript T (e.g., “this is for you” as shown in the figure below), by adding a carefully chosen small perturbation sound δ (imperceptible to people), the resulting audio I+δ can be recognized as some other targeted transcript T' (≠T, e.g., “power off”) by a speech recognition system. This composed audio I+δ is known as an audio adversarial example.
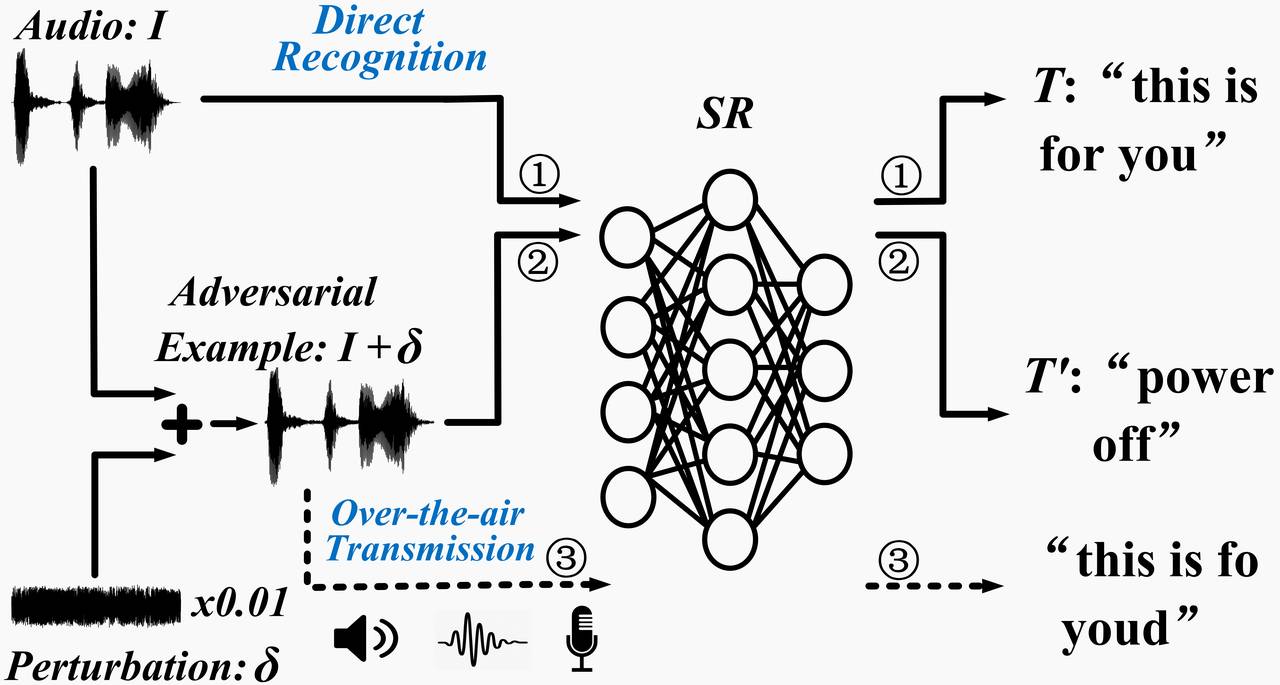
Over-the-air attacks. However, it is non-trivial to launch this attack to fool the neural network of a speech recognition (SR) system at the receiver side after the over-the-air transmission, because the effective audio signal received by SR after the transmission is H(I+δ), instead of I+δ, where H(⋅) represents the signal distortion from the acoustic channel and also the distortion from the device hardware (speaker and microphone). Due to H(⋅), the effective adversarial example may not lead to T' any more. Therefore, one open question is whether we can find a generic and robust δ that survives at any location in space, even when the attacker may not have a chance to measure H(⋅) in advance.
Metamorph Design
Understand over-the-air audio transmissions. When an attacker initializes an over-the-air attack, the audio first goes through the transmitter's loudspeaker, then enters the air channel, and finally arrives at the victim's microphone. Overall, the adversarial audio is affected by three factors: device distortion, channel effect, and ambient noise. We first experiment in an acoustic anechoic chamber (avoiding multi-path as shown in the following figure (a)) and find that as devices are optimized for humans’ hearing, the hardware distortion on the audio signal shares many common features in the frequency domain cross devices in the following figure (b) and undermines the over-the-air adversarial attack already. In practice, the problem is naturally more challenging since the channel frequency selectivity will be further superimposed, which could become stronger and highly unpredictable as the distance increases as shown in the following figure (c-d).

“Generate-and-Clean” two-phase design. Although it is difficult to separate these two frequency selectivity sources and conduct precise compensation, because the multi-path effect varies over distance and the hardware distortion shares similar features cross devices, above understanding inspires that (at least) within a reasonable distance before the channel frequency-selectivity dominates and causes H(⋅) to become highly unpredictable, we can focus on extracting the aggregate distortion effect from both device and channel. Once the core impact is captured, we can factor it into the audio adversary example generation. Therefore, we propose a “generate-and-clean” two-phase design.
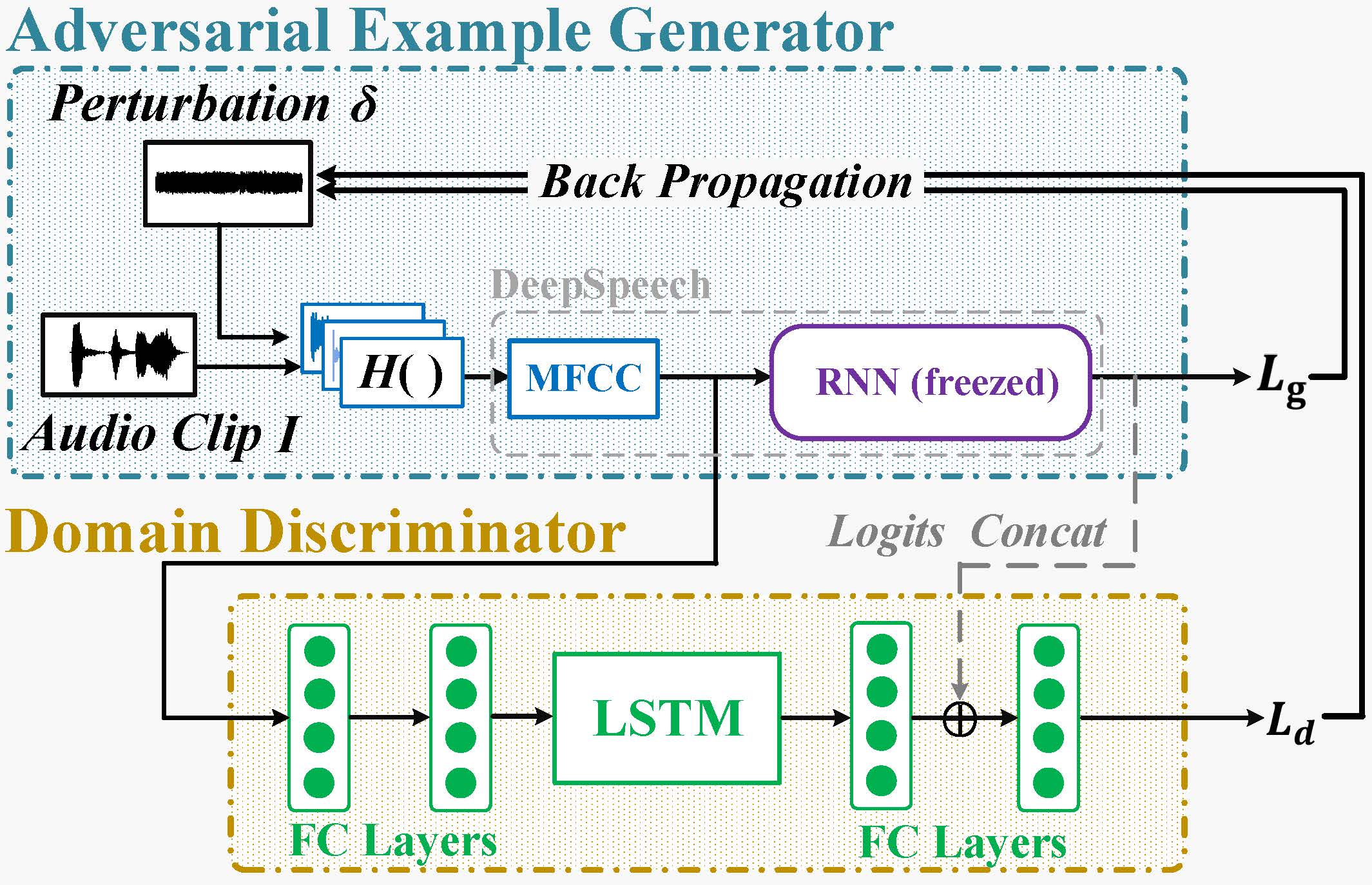
In phase one, we utilize a small set of public channel impulse response (CIR) measurements as a prior H(⋅) dataset to generate an initial δ that captures the major impact of the frequency-selectivity from these measurements (including both device and channel frequency selectivity) collected in different environments with different devices. The first phase achieves an initial success for the over-the-air attack over short links, e.g., 1 m, but this primary δ inevitably preserves some measurement-specific features, still limiting the attack performance. Therefore, in the second phase, we further leverage domain adaptation algorithms to clean δ by compensating the common device-specific feature and also minimizing the unpredictable environment dependent feature from these CIR measurements to further improve the attack distance and reliability. Finally, we also propose mechanisms to improve the audio quality of the generated adversarial examples in Metamorph.
Attack Demo
Generated Audio Adversarial Examples
Metamorph presents two versions of adversarial examples, named as Meta-Enha (when prioritized to reliability) and Meta-Qual (when prioritized to audio quality).
- Audio Group 1: Using musics as source audios
| Classical music | |||
| Pop music | |||
| Rock music | |||
| Rap music |
- Audio Group 2: Using speeches as source audios
| Example 1 | |||
| Example 2 | |||
| Example 3 | |||
| Example 4 |
Download Released Audios
Comparison of Related Works
| Schemes | Target Model | Attack Setting | Over-the-Air | Attack Scenes | Successful Rate | Audio Quality (MCD*) |
| Black-box Attacks [1, 2] |
DeepSpeech | Black-box | No | - | - | - |
| Qin et al. | Lingvo | White-box | No | Simulated | - | - |
| Carlini et al. | DeepSpeech | White-box | No | - | - | - |
| Abdullah et al. | DeepSpeech | White-box | Yes | 0.3 m (1 foot) | 15/15 (trials) | - |
| CommanderSong | Kaldi | White-box | Yes | 1.5 m | 78% | 22.3 |
| Yakura et al. | DeepSpeech | White-box | Yes | 0.5 m | 80% | 25.1 |
| Meta-Enha | DeepSpeech | White-box | Yes | 6 m (LoS) | 90% | 25.2 |
| Meta-Qual | DeepSpeech | White-box | Yes | 3 m (LoS) | 90% | 21.1 |
*Lower MCD value indicates better sound quality.
Cite Metamorph
Authors:
- Tao Chen at City University of Hong Kong
- Longfei Shangguan at Microsoft
- Zhenjiang Li at City University of Hong Kong
- Kyle Jamieson at Princeton University
This paper is published at NDSS 2020.
Cite the Paper
@inproceedings{tao2020Metamorph,
author = {Chen, Tao and Shangguan, Longfei and Li, Zhenjiang and Jamieson, Kyle},
title = {Metamorph: Injecting Inaudible Commands into Over-the-air Voice Controlled Systems},
booktitle={Proceedings of NDSS},
year = {2020}
}